

代码拉取完成,页面将自动刷新
同步操作将从 Ascend/ModelLink 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
![]()


简体中文 | English
ModelLink旨在为华为 昇腾芯片 上的大语言模型提供端到端的解决方案, 包含模型,算法,算子,以及下游任务。
当前ModelLink支持下列模型的预训练以及全参微调:
当前ModelLink为大模型提供以下周边应用:
强化学习,多专家网络等特性持续研发中....
当前ModelLink支持以下分布式加速算法:
更多高效的加速算法正在为昇腾芯片上的大语言模型研发中...
即将上线 ...
| 模型 | 参数 | 节点 | 模式 | 昇腾 | 参考 | Loss | 脚本 |
|---|---|---|---|---|---|---|---|
| Aquila | 7B | 1x8 | FP16 | 3394 | 4078 | Loss | 训练 |
| Baichuan | 7B | 1x8 | FP16 | 2350 | 2036 | Loss | 训练 |
| 13B | 1x8 | FP16 | 1016 | 824 | Loss | 训练 | |
| Baichuan2 | 7B | 1x8 | BF16 | 2607 | 3936 | Loss | 训练 |
| 13B | 2x8 | BF16 | 852 | 872 | Loss | 训练 | |
| Bloom | 7B1 | 1x8 | FP16 | 2611 | 2525 | Loss | 训练 |
| 176B | 12x8 | BF16 | 112 | 107 | Loss | 训练 | |
| InternLM | 7B | 1x8 | BF16 | 2943 | 4078 | Loss | 训练 |
| 65B | 4x8 | BF16 | 342 | 414 | Loss | 训练 | |
| LLaMA | 7B | 1x8 | FP16 | 3600 | 3804 | Loss | 训练 |
| 13B | 1x8 | FP16 | 1895 | 2012 | Loss | 训练 | |
| 33B | 4x8 | FP16 | 635 | 776 | Loss | 训练 | |
| 65B | 4x8 | ||||||
| BF16 | 348 | 426 | Loss | 训练 | |||
| LLaMA2 | 7B | 1x8 | BF16 | 2681 | 2884 | Loss | 训练 |
| 13B | 1x8 | BF16 | 1485 | 1750 | Loss | 训练 | |
| 34B | 2x8 | BF16 | 690 | 796 | Loss | 训练 | |
| 70B | 8x8 | BF16 | 350 | 339 | Loss | 训练 |
| 软件 | 版本 |
|---|---|
| Python | 3.8.18 |
| driver | 2023Q4商发 |
| firmware | 2023Q4商发 |
| CANN | 2023Q4商发 |
| binary arithmetic package | 2023Q4商发 |
| torch | 2.1.0 |
| torch_npu | 2023Q4商发 |
| 模型 | 参数 | 微调 | 推理 | 评估 | 数据集 |
|---|---|---|---|---|---|
| Aquila | 7B | -- | 对话 | 评估 | alpaca_data.json |
| Baichuan | 7B | -- | -- | -- | alpaca_data.json |
| 13B | lora | 对话 | 评估 | alpaca_data.json | |
| Bloom | 7B1 | lora | 对话 | 评估 | alpaca_data.json |
| 176B | -- | 对话 | 评估 | alpaca_data.json | |
| InternLM | 7B | -- | 对话 | 评估 | alpaca_data.json |
| LLaMA | 7B | lora | 对话 | 评估 | alpaca_data.json |
| 13B | lora | 对话 | 评估 | alpaca_data.json | |
| 33B | lora | 对话 | 评估 | alpaca_data.json | |
| 65B | -- | 对话 | 评估 | alpaca_data.json | |
| LLaMA2 | 7B | lora | 对话 | 评估 | alpaca_data.json |
| 13B | -- | 对话 | 评估 | alpaca_data.json | |
| 34B | -- | 对话 | 评估 | alpaca_data.json | |
| 70B | -- | 对话 | 评估 | alpaca_data.json |
# 对于llama, 可以下载alpaca数据集, 比如
wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
# 下载 tokenizer 配置, 地址:
# https://huggingface.co/yahma/llama-7b-hf/tree/main
# 这里要将tokenizer_config.json中的"LLaMATokenizer"修改为"LlamaTokenizer"(这是huggingface的一个bug)
mkdir dataset
python tools/preprocess_data.py --input train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix dataset/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler
# 这里认为 数据集 和 tokenizer 已经下载放到了 WORKSPACE.
cd WORKSPACE
mkdir wikipedia_preprocessed
hf_config_json="./hf_config_json.json"
cat <<EOT > $hf_config_json
{
"path": "WORKSPACE/wikipedia",
"name": "20220301.en",
"streaming: True,
"split": "train"
}
EOT
python tools/preprocess_data.py \
--input "WORKSPACE/wikipedia" \
--hf-datasets-params ${hf_config_json} \
--output-prefix WORKSPACE/wikipedia_preprocessed/wikipedia \
--dataset-impl mmap \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--streaming \
--workers 8
处理完后, WORKSPACE/wikipedia_preprocessed 文件夹下会有 wikipedia_text_document.bin 和 wikipedia_text_document.idx 文件, 我们便可以使用 --data-path WORKSPACE/wikipedia_preprocessed/wikipedia_text_document 标志训练模型了
请注意huggingface中的数据集格式是这样的. 我们处理数据时利用的数据列可以通过 --json-key 标志设置,默认为 text,
比如,wikipedia数据集有四列, 包括 id, url, title 和 text, 我们就可以通过 --json-key 标志选择一列处理该数据集
此外, 我们也可以使用 alpaca 数据集用于预训练如下:
python tools/preprocess_data.py --input WORKSPACE/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix WORKSPACE/alpaca_preprocessed/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--json-key text
# 数据集:wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
cd WORKSPACE
mkdir alpaca_preprocessed
python tools/preprocess_data.py --input WORKSPACE/alpaca/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix WORKSPACE/alpaca_preprocessed/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler \
--append-eod
在处理后,WORKSPACE/alpaca_preprocessed 文件夹下会有3个 bin 文件 和 3个 idx 文件,我们便可以通过添加 --data-path WORKSPACE/alpaca_preprocessed/alpaca 和 --is-instruction-dataset 标志来进行指令微调。
此外,基于指令数据集,我们还可以通过加上 --variable-seq-lengths 标志使用动态序列长度训练模型。
请注意,使用 --handler-name GeneralInstructionHandler 标志的指令数据集,在处理时会从 ascendspeed/data/data_handler.py 中选择 GeneralInstructionHandler 类来制作prompt。如果你处理的是 alpaca 格式风格的数据集,即包含 instruction, input 和 output 列的数据集,可以直接使用 --handler-name GeneralInstructionHandler 标志。
此外,BelleMultiTurnInstructionHandler 可以被用于处理 belle 格式的数据集,MOSSInstructionHandler 可以被用于处理 MOSS 格式的数据集,LeetcodePythonInstructionHandler 可以被用于处理 Leetcode 风格的数据集
当前 ModelLink基于 peft 仓库支持对大模型的 Lora 微调功能:
pip install peft==0.4.0
当torch==1.11.0的时候,你也可以选择直接从它Github仓库的 源码安装, 通过修改它的setup.py文件来回避一些依赖问题。
之后,你仅仅只需要在启动脚本中使能如下标志便可以启动lora微调训练:
# Llama example
--lora-target-modules query_key_value dense gate_proj dense_h_to_4h dense_4h_to_h \
Lora有一些相关参数,在 PEFT 仓库中有详细介绍,比如:
# Llama example
--lora-r 64 \
--lora-alpha 128 \
--lora-modules-to-save word_embeddings output_layer \
--lora-register-forward-hook word_embeddings input_layernorm \
在这些参数中,标志 --lora-register-forward-hook 被用于修复由PP造成的梯度链中断,它仅仅只需要在每一个PP阶段的输入层设置,并不会增加训练参数。 标志 --lora-modules-to-save 被用于扩展词表时的微调,若没此需求则无需传入此参数。
最后,Lora微调后保存的权重仅仅只会包含新增的Lora权重。相似的,当你加载一个Lora模型时,除了原始权重路径需要设置,还需要设置一个加载Lora权重的路径,如下:
--load ${ORIGIN_CHECKPOINT} \
--lora-load ${LORA_CHECKPOINT} \
这个 例子 可以用于参考。
在使用 Lora 微调 Llama 模型以后,指令对话的效果如下:
You >> Give three tips for staying healthy.
AscendSpeed:
- Start exercising regularly and eat healthy food.
- Get a good eight hours of sleep each night.
- Take medications regularly.
如果在完成lora微调后,需要一个不带lora结构的模型,那么我们只需运行这个 脚本,即可将--load和--lora-load这两个模型文件合并,生成的不带lora结构的新权重模型文件存在--save路径里。
当前,我们支持使用如下并行策略训练的模型进行推理:
这里有一些使用不同模式的样例脚本可以尝试运行,请注意:
如果你尝试使用 huggingface 的模型权重,请首先进行权重转换, 以 Llama-7B 为例:
PTD 策略的转换
python tools/ckpt_convert/llama/convert_weights_from_huggingface.py --input-model-dir llama-7b-hf \
--output-model-dir llama-7b-tp2-pp2 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 2 \
--type 7B
ZeRO 策略的转换
python tools/ckpt_convert/llama/convert_weights_from_huggingface.py --input-model-dir llama-7b-hf \
--output-model-dir llama-7b-deepspeed \
--type 7B \
--deepspeed
下面脚本中的一些路径需要修改,比如:模型权重路径 和 词表路径.
sh examples/llama/generate_llama_7B_tp2_pp2.sh
sh examples/alpaca/generate_alpaca_13B_deepspeed.sh
sh examples/llama/generate_llama_7B_deepspeed_pipeline.sh
sh examples/alpaca/generate_alpaca_13B_lora_deepspeed.sh
这里列举了一些使用 Chinese-LLaMA-Alpaca-13B 权重进行推理的例子, 同时依据下列步骤可以写出你自己的推理例子:
initialize_megatron(args_defaults={'no_load_rng': True, 'no_load_optim': True})
from modellink import get_args
from modellink.model import GPTModel
from modellink.arguments import core_transformer_config_from_args
def model_provider(pre_process=True, post_process=True):
"""Build the model."""
config = core_transformer_config_from_args(get_args())
init_model = GPTModel(
config,
num_tokentypes=0,
parallel_output=False,
return_moe_loss=False,
pre_process=pre_process,
post_process=post_process
)
return init_model
model = GPTModel.from_pretrained(
model_provider=model_provider,
pretrained_model_name_or_path="your model weight path"
)
"""
This is an API for initializing model and loading weight.
Parameters:
----------
model_provider(`func`):
Function used to generate model objects which is similar to the training define.
pretrained_model_name_or_path(`str`, *optional*, defaults to None):
File path of Model weight in megatron format (TP, PP may be used).
If it is None, the random initialized weights will be used.
"""
Greedy Search
responses = model.generate(
"Write quick sort code in python",
max_new_tokens=512
)

Do sample with top-k and top-p
responses = model.generate(
"Write quick sort code in python",
do_sample=True,
temperature=1.0,
top_k=50,
top_p=0.95,
max_new_tokens=512
)

Beam search with top-k and top-p
responses = model.generate(
"Write quick sort code in python",
num_beams=4,
top_k=50,
top_p=0.95,
max_new_tokens=512
)

Beam search with top-k and top-p sampling
responses = model.generate(
"Write quick sort code in python",
do_sample=True,
temperature=0.6,
num_beams=4,
top_k=50,
top_p=0.95,
max_new_tokens=512
)

| 任务 | 验证集 | 模型 | 昇腾值 | 参考值 | 社区值 |
|---|---|---|---|---|---|
| BBH | Test | Llama7b | 0.334 | 0.333 | 0.335 |
| AGIEval | Test | Llama7b | 0.210 | 0.210 | 0.206 |
| HumanEval | Test | Llama7b | 0.128 | 0.128 | 0.128 |
| BoolQ | test | Llama7b | 0.742 | 0.742 | 0.754 |
| GSM8K | Test | Llama7b | 0.102 | 0.103 | 0.100 |
| CEval | Validation | Llama7b | 0.408 | 0.404 | / |
| MMLU | test | Llama7b | 0.333 | 0.324 | 0.351 |
# 配置模型和词表路径
# 词表路径地址:https://huggingface.co/yahma/llama-7b-hf
CHECKPOINT=../models/llama-7b-tp2-pp4/
VOCAB_FILE=../models/llama7b-hf/
# 配置任务和数据路径
DATA_PATH="dataset/boolq/test"
TASK="boolq"
# 配置生成参数
python -m torch.distributed.launch $DISTRIBUTED_ARGS evaluation_llama.py \
--task-data-path $DATA_PATH \
--task $TASK\
--seq-length 512 \
--max-new-tokens 1 \
--evaluation-batch-size 1 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load ${CHECKPOINT[images](sources%2Fimages)} \
--num-attention-heads 32 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path $VOCAB_FILE \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seed 42 | tee logs/train.log
# 开启评估
bash tasks/evaluation/eval_llama.sh
最重要的评估参数是 --max-new-tokens, 它表示模型输出的生成长度,比如,多项选择问题的输出长度就会明显比编码任务的输出长度小,该参数也很大程度上影响了模型的生成速度。
python -m torch.distributed.launch $DISTRIBUTED_ARGS evaluation_llama.py \
--task-data-path $DATA_PATH \
--task $TASK\
--seq-length 512 \
--max-new-tokens 1 \
--evaluation-batch-size 1 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load ${CHECKPOINT} \
--num-attention-heads 32 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path $VOCAB_FILE \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seed 42 | tee logs/train.log
BoolQ 是一个 yes/no 的问答数据集, 每一个问题包含了一个(问题,文章,答案)三元组,同时有文章的标题作为额外的选择性输入。BoolQ 数据集的评估相对简单,只需要配置 TASK="boolq", --seq-length=512, --max-position-embeddings=512, --max-new-token=1。
零样本评估的结果通常会被给定的 prompt 影响,可以尝试通过在 tasks/evaluation/evaluation.py 中设置合适的 prompt 得到更高的分数,
# 通过修改 template 更新prompt
template = {instruction}
由于 MMLU 是一项多学科任务,并且需要进行 5-shot 评估,因此每个学科问题的长度差异很大。如果你想同时跑57个学科任务,可以尝试设置 TASK="mmlu", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=1 。
在很多网站,MMLU 的精度会依据学科进行评估,57个学科主要属于四个大类, 因此该数据集也可以基于四个大类进行打分,网站 给出了具体的57个类别。
GSM8K 是一个有8.5k高质量小学数学应用题文本的数据集,每一个问题的回答是具体的数字。由于该数据集通常采用 few-shot 的形式进行评估,GSM8K的问题长度相对是比较长的,输出答案包含一整个思维链路,相关入参应该设置为 TASK="gsm8k", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=200.
HumanEval 是一个用于挑战代码生成问题的数据集,具有164个编程问题,包含函数签名,文档,函数主体和单元测试等。该数据的所有问题都是手写的,以确保它们不在训练集中,由于答案包含长代码,相关参数可以设置为 TASK="human_eval", --seq-length=2048,
--max-position-embeddings=2048, --max-new-token=200。
AGIEval 是一个用于评估大模型在人类认知和问题解决能力方面生成能力的基准数据集,它源于20个面向普通考生的官方、公开和高标准的入学和资格考试,相关参数可以设置为 TASK="agieval", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=5。
Big-bench-hard 数据集是 BIG-Bench 的一个子集,专注于有挑战性的23个 BIG-Bench 任务, 涵盖文本理解、推理、逻辑推理、数学推理和常识推理等多个领域,相关参数可以设置为 TASK="bbh", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=32,--evaluation-batch-size=4。
如 C-Eval 展示的, C-Eval 是一个针对大模型的综合中文评估数据集, 它由13948道多项选择题组成,涵盖52个不同学科和4个难度级别,划分为验证和测试集,验证集包含标签用于个人评估,测试集合的标签没有公开,如果想要知道模型得分,需要将结果 邮件发送给 C-Eval,相关参数可以设置为 TASK="ceval", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=1。
张量并行(Tensor Parallelism,TP)是一种模型并行策略,它将单个Transformer模块的执行拆分到多个设备上,以均分内存消耗。TP的基本原理如下:


--tensor-model-parallel-size 标志, 来明确用于拆分模型的GPU数量。
流水并行(Pipeline Parallelism (PP))是一种将模型所有的Transformer模块划分为多个stage放在不同卡上训练的模型并行技术。 在PP中,每一个stage都有相等数量的Transformer,同时通过将 全局的 (global) batchsize 拆分为多个 微 (micro) batchsize,在stage间流水化训练这些微 batchsize,以达到训练整个模型的目的。 虚拟流水并行 (Virtual Pipeline (VP) Parallelism),通过增加虚拟的 stage 来减少 PP 运行时的空泡时间, 动态流水并行 (Dynamic Pipline Parallelism,DPP) 则是增强版本的 VP, 通过合理的设置每个微 batchsize的大小进一步降低空泡时间。 PP 和 VP的基本原理如下:

在ModelLink中,可以通过使能--pipeline-model-parallel-size 标志来明确PP要将模型划分为多少个 stage,比如,该参数设置为4,就是将一个具有24层transformer的模型划分为4个stage,每个stage有6层transformer。
为了使用VP,需要额外添加 --num-layers-per-virtual-pipeline-stage 标志,来决定每个虚拟stage的层数;目前仓库支持的VP形式为VP + no-overlap-p2p,当要开启VP时候,需要加入 --no-overlap-p2p-communication参数关闭overlap-p2p。为了使用DPP,则需要在PP的基础上添加 --optimized-pipeline 和 --manual-mbs example-config-1 标志。需要说明的是,虽然VP和DPP可以减少空泡时间,但是会增加通讯时间。
Fold3D 隐藏了 PP 中数据并行的通信时间,其基本原理如下:

--fold-mode "aiao" 标志可以打开该功能。
为了使用有限的显存来训练更大的模型,ModelLink 支持完全重计算以及选择性重计算策略,为了使能完全重计算,可以使用 --checkpoint-activations 标志,
至于选择性重计算,则可以通过添加 --checkpoint-policy 标志来决定选择性重计算的策略。
为了最大限度地利用NPU内存,同时提高模型训练的性能,我们支持通过调整训练内存大小的方式,自动获取选择重计算策略,这一特性称为自适应选择重计算。
启用自适应选择重计算,请使用--auto-recompute-device-size标志指定自适应选择重计算策略的训练内存大小(单位:MB)。请注意,如果要使用--auto-recompute-device-size标志,请删除标志--checkpoint-activations。
如果发生OOM,您需要重新选择一个内存值来重启模型训练。您也可以通过二分法的方式获得最优解。
自适应选择重计算根据profiling前N步的训练内存信息进行策略选择,您可以通过使用--auto-recompute-profiling-step标志设置停止profiling的步数。
默认在第10步停止profiling,最小设置为5步,建议在训练内存平稳后停止profiling,这样可以获得更佳的选择重计算策略。
序列并行(Sequence Parallelism,SP)是一种模型并行策略,它依赖TP的实现,沿着序列轴按照TP的维度拆分了dropout层和layernorm层。 SP将TP中的allreduce操作拆分为了reduce-scatter和allgather操作,这降低了模型训练中的内存占用。

为了使能SP, --tensor-model-parallel-size 标志应该大于1,同时设置 --sequence-parallel 标志。
无冗余优化器(Zero Redundancy Optimizer,ZeRO)是微软提出的一种在数据并行中优化内存的并行策略。ModelLink通过增加deepspeed分支,支持了ZeRO-1/2,其基本原理如下:

为了使能ZeRO-1/2, 我们需要配置一个如 例子 所示的deepspeed config。
值得一提的是,如果仅仅是需要ZeRO-1,那么deepspeed不是必须的,只需要设置 --use-distributed-optimizer 标志就可以了。
倒三角在python层面实现了flash attention,是一种针对attention模块的加速算法。基本的,self-attention在计算attention值的时候会把整个attention mask纳入计算, 而倒三角加速算法仅仅会计算必要的部分,从而降低计算量,计算过程如下:

在ModelLink中可以通过使能 --triangle-attn 标志打开倒三角加速。
融合优化器通过减小算子下发降低计算时间,在ModelLink中,通过 --optimizer 可以选择不同的优化器,具体的,选择 --optimizer adam 可以节省更多内存,选择 --optimizer fused_adam 则可以运行的更快。
除此之外,我们还提供一些自研的低内存优化器。如:
Cadam是基于谷歌提出的Lion优化器,并采用与其beta参数相同的极简形式。这样在去掉二阶动量的同时,可以得到类似于Adam的参数更新效果。然后对一阶动量进行量化和逐行压缩,采用昇腾亲和的FP16进行计算,同时结合Scale和clip操作防止溢出。

欲使用Cadam优化器,需要在脚本中指定如下参数--optimizer cadam,并将能够用Adam正常平稳训练的模型的学习率lr和最小学习率min-lr缩小3-10倍,weight_decay同步放大3-10倍,--adam-beta1 0.965。
部分大模型的测试结果如下表所示:
| 模型 | 优化器 | 性能 | 平均压缩HBM | BoolQ | PIQA | HellaSwag |
|---|---|---|---|---|---|---|
| LLama-7B | Adam | 5.65s/iteration | -- | 38.78% | 52.88% | 26.69% |
| Cadam | 5.68s/iteration | ↓ 21.8% | 41.50% | 55.11% | 26.59% | |
| LLama2-7B | Adam | 7.09s/iteration | -- | 40.36% | 51.20% | 25.13% |
| Cadam | 7.12s/iteration | ↓ 17.4% | 44.16% | 51.20% | 26.29% | |
| Bloom-7B | Adam | 4.10s/iteration | -- | 37.83% | 49.24% | 25.31% |
| Cadam | 4.25s/iteration | ↓ 10.1% | 37.83% | 51.16% | 25.25% |
对于llama以及一些在FFN中没有bias的模型,FFN中的线性层可以合并计算以减少TP中的通信量,通过设置 --mlp-layer-fusion 标志,可以使用该特性。
梯度累积基于 N 轮梯度更新一次参数,这里的 N = global batchsize / micro batchsize / DP,DP = device nums / tp / pp。
混合精度训练中,需要保存参数副本、梯度副本、优化器状态等多种状态张量,占据了大量的静态内存(16N,N为参数量),而实际参与前反向计算的参数和梯度(4N,N为参数量)相比之下占比很小,优化以上状态张量可以带来极大的显存收益。本算法希望通过深入分析每部分状态张量的实际使用实现机制的显存复用,最终得到一个集成多个算法模块的多级优化器内存优化方案。
Foreach+Cast操作转换成FP32的形式,可节省4N的空间。--release-fp32-grad触发。原始混合精度训练流程:
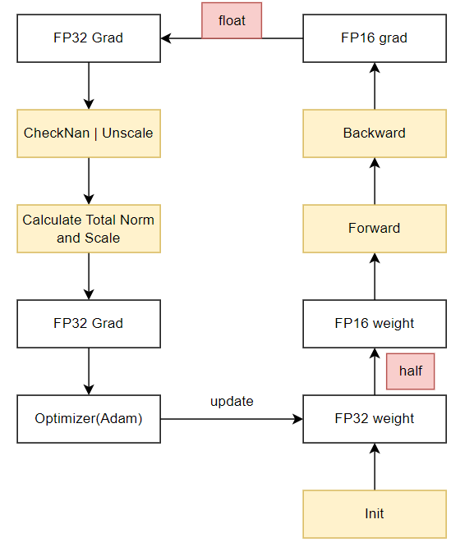
内存复用O1训练流程:
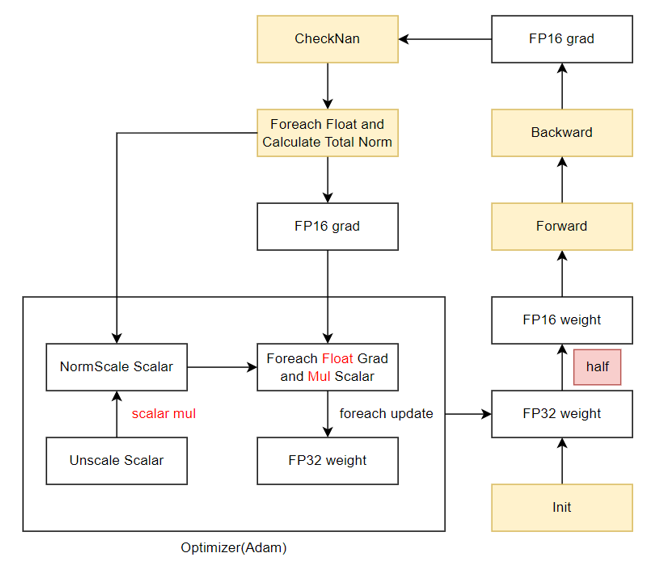
部分模型测试结果如下表:
| Model | Algorithm | Performance | Compress HBM | Performance Error | Precision Error | Hardware |
|---|---|---|---|---|---|---|
| LLama-7B | baseline | 5.39s/iteration | -- | -- | -- | 910B*8P |
| O1 algorithm | 5.40s/iteration | ↓ 13.5% | ↓ 0.17% | < 0.05% | 910B*8P | |
| LLama-13B | baseline | 8.95s/iteration | -- | -- | -- | 910B*8P |
| O1 algorithm | 8.92s/iteration | ↓ 14.90% | ↑ 0.34% | < 0.2% | 910B*8P | |
| LLama2-7B | baseline | 6.48s/iteration | -- | -- | -- | 910B*8P |
| O1 algorithm | 6.48s/iteration | ↓ 10.87% | ↓ 0.00% | < 0.2% | 910B*8P | |
| Bloom-7B | baseline | 5.45s/iteration | -- | -- | -- | 910B*8P |
| O1 algorithm | 5.49s/iteration | ↓ 12.68% | ↓ 0.7% | < 0.01% | 910B*8P | |
| LLama-32B | baseline | 5.23s/iteration | -- | -- | -- | 910B*16P |
| O1 argorithm | 5.28s/iteration | ↓ 15.93% | ↓ 0.95% | < 0.02% | 910B*16P | |
| LLama-7B | distributed baseline | 5.18s/iteration | -- | -- | -- | 910B*8P |
| O1 distributed algorithm | 5.19s/iteration | ↓ 9.50% | ↓ 0.2% | < 0.1% | 910B*8P |
ModelLink由华为公司的下列部门联合贡献 :
感谢来自社区的每一个PR,欢迎贡献 ModelLink
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}